深度学习的最后一天
今天看了很多当时年代的各种神经网络,不禁好奇,究竟什么是transform,transform与其他的神经网络有什么区别
在解决这个问题之前,我想,在这25年的最后的一天里,在这个除夕里,写下对这本书最后的总结以及自己读这本书的感受,那话不多说,我们开始
深度学习的层次的意义
如何提高识别的精度
- 增加神经网络的深度
- 经过研究和推导,我们可以很轻易的发现,在增加神经网络的层次之后,我们会发现参数的个数会减小,这意味着我们可以花费更少的资源 来训练我们的神经网络
- 可以使得学习更加高效。我们知道随着层次的增加,我们可以发现卷积核的识别出来的图像变得更加具体,也就是从点线面变成具体的物体,比如小狗小猫等等
- 通过加深层,可以分层次地传递信息。通过加深层,可以将各层要学习的问题分解成容易解决的简单问题,从而可以进行高效的学习
- Data Augmentation(数据扩充) 何为数据扩充?简单来说就是对数据进行旋转和平移操作从而扩充输入图像(训练图像)
- 集成学习、学习率衰减等方法
深度学习的一些历史
ImageNet是拥有超过100万张图像的数据集。如图8-7所示,它包含
了各种各样的图像,并且每张图像都被关联了标签(类别名)。每年都会举办
使用这个巨大数据集的ILSVRC图像识别大赛。

一些排名前列的识别策略
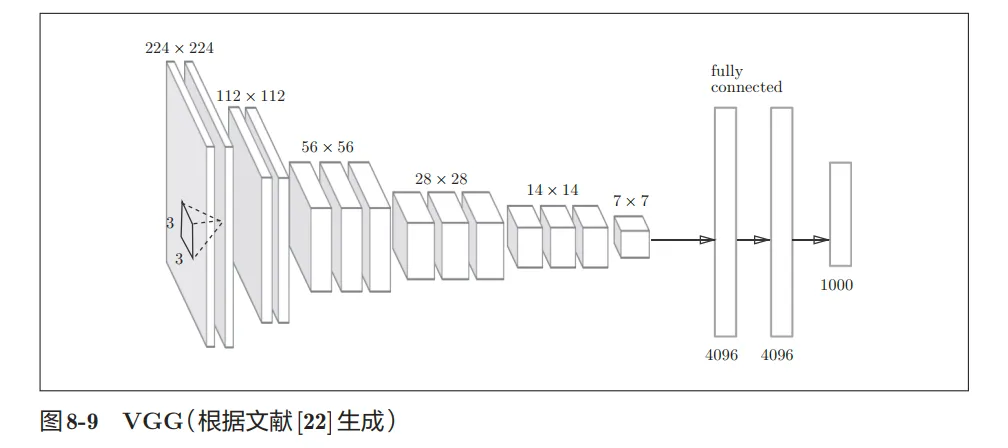
- VGG :
- VGG是由卷积层和池化层构成的基础的CNN。它的特点在于将有权重的层(卷积层或者全连接层)叠加至16层(或者19层),具备了深度(根据层的深度,有时也称为“VGG16”或“VGG19”)
- VGG的卷积核是连续运行的,重复进行“卷积层重叠2次到4次,再通过池化层将大小减半”的处理
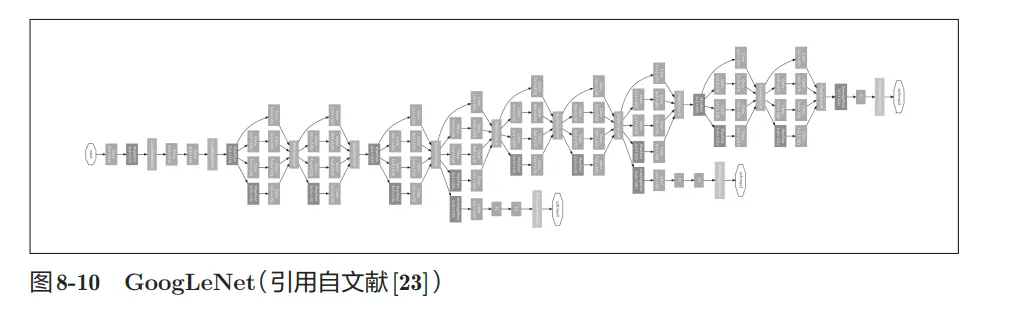
- GoogLeNet:
- GoogLeNet的特征是,网络不仅在纵向上有深度,在横向上也有深度(广度)
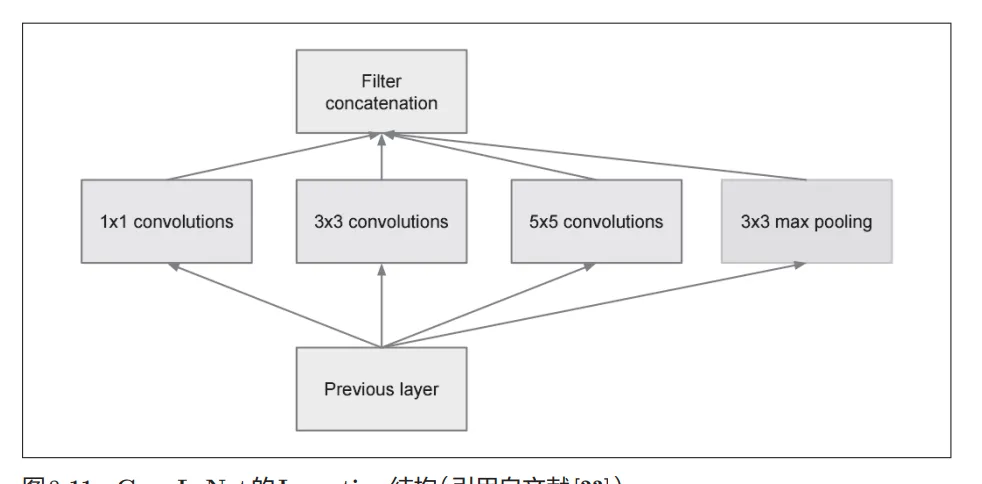
- “宽度”称为“Inception结构”,, Inception结构使用了多个大小不同的滤波器(和池化),最后再合并它们的结果。 GoogLeNet的特征就是将这个Inception结构用作一个构件(构成元素)。
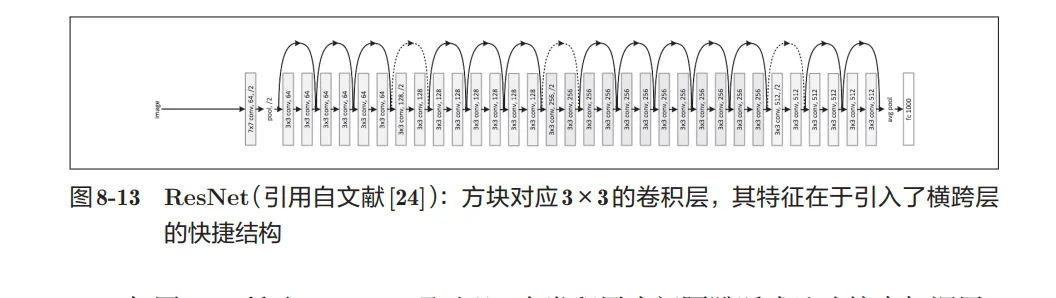
- ResNet:
- 在深度学习中,过度加深层的话,很多情况下学习将不能顺利进行,导致最终性能不佳.于是微软提出了ResNet
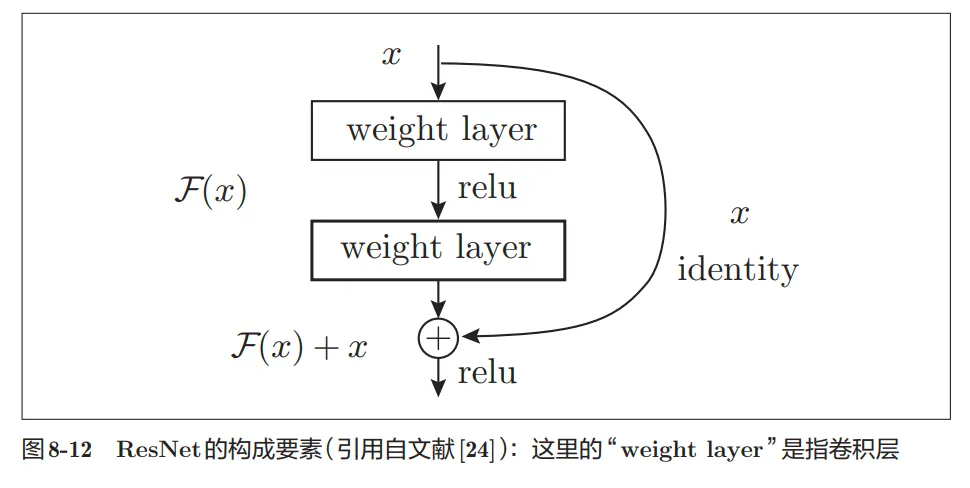
- 导入了“快捷结构”(也称为“捷径”或“小路”)。导入这个快捷结构后,就可以随着层的加深而不断提高性能了
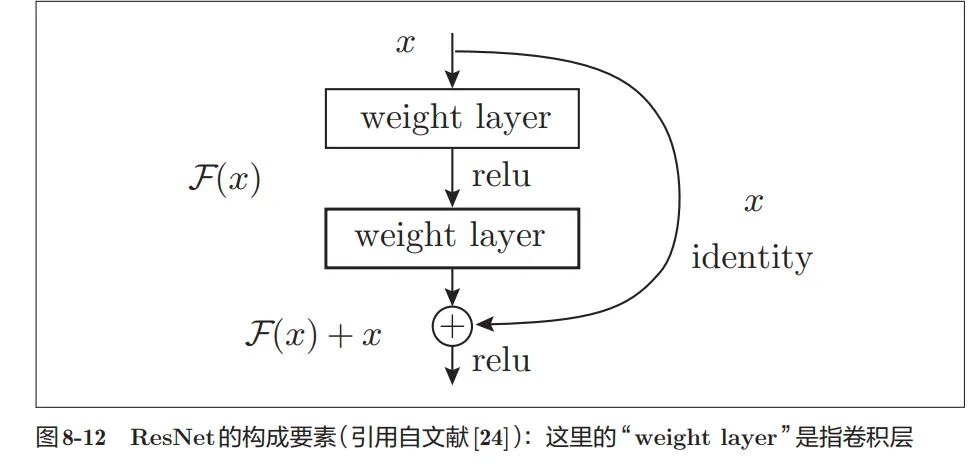
- 因为快捷结构只是原封不动地传递输入数据,所以反向传播时会将来自上游的梯度原封不动地传向下游。这里的重点是不对来自上游的梯度进行任何处理,将其原封不动地传向下游。因此,基于快捷结构,不用担心梯度会变小(或变大),能够向前一层传递“有意义的梯度”。
- 简单来说就是定义$输出 = 残差+上一层的输入$,主要解决的问题其实是比如说预测一只猫,前一层已经给出了正确的结果,但是如果在之前的定义下,那有可能下一层就会重复计算,算出来一只红色的猫,不仅重复还多余。在引入残差之后呢,当预测的结果和标签已经相同的情况下,下一层的输出就是$0 + 上一层的输出$,可见还是上一层的输出,这样就提高了效率,结构如下图所示:
迁移学习:实践中经常会灵活应用使用ImageNet这个巨大的数据集学习到的权重数据,学习完的权重(的一部分)复制到其他神经网络,进行再学习(fine tuning)。比如,准备一个和 VGG相同结构的网络,把学习完的权重作为初始值,以新数据集为对象,进行再学习。迁移学习在手头数据集较少时非常有效。
深度学习的高速化
加速策略分析
AlexNex中,大多数时间都被耗费在卷积层上。实际上,卷积层的处理时间加起来占GPU整体的95%,占CPU整体的89%!因此,如何高速、高效地进行卷积层中的运算是深度学习的一大课题
而卷积层中进行的运算可以追溯至乘积累加运算。因此,深度学习的高速化的主要课题就变成了如何高速、高效地进行大量的乘积累加运算。
选GPU还是CPU
我们先比较一下GPU和CPU的区别
GPU:擅长并行计算矩阵的乘法和加法
CPU:适合比较擅长连续的、复杂的计算)
综上,我们选择GPU作为我们的训练基础,那显卡选哪家的呢?GPU主要由NVIDIA和AMD两家公司提供。虽然两家的GPU都可以用于通用的数值计算,但与深度学习比较“亲近”的是NVIDIA的GPU。事实上,因为深度学习的框架中使用了NVIDIA提供的CUDA这个面向GPU计算的综合开发环境
分布式计算
- 如果一个计算任务太重、太大,一台计算机(哪怕是超级计算机)算不动或者算得太慢,我们就把这个任务拆分成很多小份,分给成百上千台普通的计算机去同时计算。这些计算机通过网络连接,协同工作,在外人看来就像是一台超级强大的计算机在运行。
- 分布式计算主要解决的问题是要调试出好的参数肯定是要经过多重的计算的,与设置比较小的epoch相同,分布式计算可以降低时间成本
运算过程中的精度降低
在高速化的阶段,除了计算量之外,内存容量、总线带宽等也有可能成为瓶颈。
-
关于内存容量,需要考虑将大量的权重参数或中间数据放在内存中。
-
关于总线带宽,当流经GPU(或者CPU)总线的数据超过某个限制时,就会成为瓶颈。考虑到这些情况,我们希望尽可能减少流经网络的数据的位
考虑到这些情况,我们希望降低存储参数的精度。深度学习的一个重要的性质是,我们对于数据的精度其实要求并不是很高,这可以从便输入图像附有一些小的噪声,输出结果也仍然保持不变。正是因为有了这个健壮性,流经网络的数据即便有所“劣化”,对输出结果的影响也较小。
计算机中表示小数时,有32位的单精度浮点数和64位的双精度浮点数等格式。根据以往的实验结果,在深度学习中,即便是16位的半精度浮点数(half float),也可以顺利地进行学习。
深度学习的一些案例
- 物体检测
- 图像分割
- 图像标题的生成:我们将组合图像和自然语言等多种信息进行的处理称为多模态处理。多模态处理是近年来备受关 注的一个领域
- 图像分割
- 图像的生成
- 自动驾驶:因为要正确识别时刻变化的环境、自由来往的车辆和行人是非常困难的。
- Deep Q-Network(强化学习):
- 在Q学习中,为了确定最合适的行动,需要确定一个被称为最优行动价值函数的函数。为了近似这个函数, DQN使用了深度学习(CNN)