昨天偷懒没有写总结,今天开补
省流版
这两天读了第四章和第五章,第四章的主要内容是让神经网络学会学习,第五章的内容主要是优化数值计算梯度的方法为反向传递法计算梯度, 话不多说,我们现在就开始了
目录
- 第一节:让神经网络开始学习
- 第二节:如何算得更快
第一节:让神经网络开始学习
从数据中学习
神经网络的核心是让机器自动从数据中学习并且更新参数
只要数据确实是可通过一位平面内的某条直线可以分开,那么一定可以通过有限次数的调整參数,使得分开实现,但是如果是混在一起的,非线性可分的话,那我们就可以多设置几层感知机,设置激活函数,也就是神经网络来实现分类
修改的具体定理:感知机收敛定理

具体举例来看: 核心其实是$W*X + B$, $W = {{\omega_1 + \omega_2}}$,
$X = {x, y},控制方向$,$B = b(控制位置)$
所以通过这个方法,我们就可以去分开两个点了,比如
现在{(1,1)(标签为0),(1,2)(标签为1}
区分这两个点,我们假设初始的权重为
$\omega = {0,0},b = 0$,预测{1,2}为0,则
$\omega_{new} = {0,0}+1{1,2} = {1,2},b = 1$,
此时此刻的方程转化为$x + 2y + 1 = 0$
此时此刻(1,2)符合条件,但是(1,1)不符合,
$\omega_{new} = {1,2}-{1,1} = {0,1},b = 0$,
方程转化为$y = 0$
$\omega_{new} = {0,1}-{1,1} = {1,0},b = -1$,
方程转化为$x - 1 = 0$
于是得到了区分的方程呀 哦耶!
那如果是线性不可分怎么办呢?此时此刻就需要请出我们的参数+激活函数的双大招了,激活函数的作用其实就是扭曲空间(斗尊强者,扭曲空间之力),
激活函数,恐怖如斯
接下来,我们对比一下传统的机器学习和深度学习的区别是什么
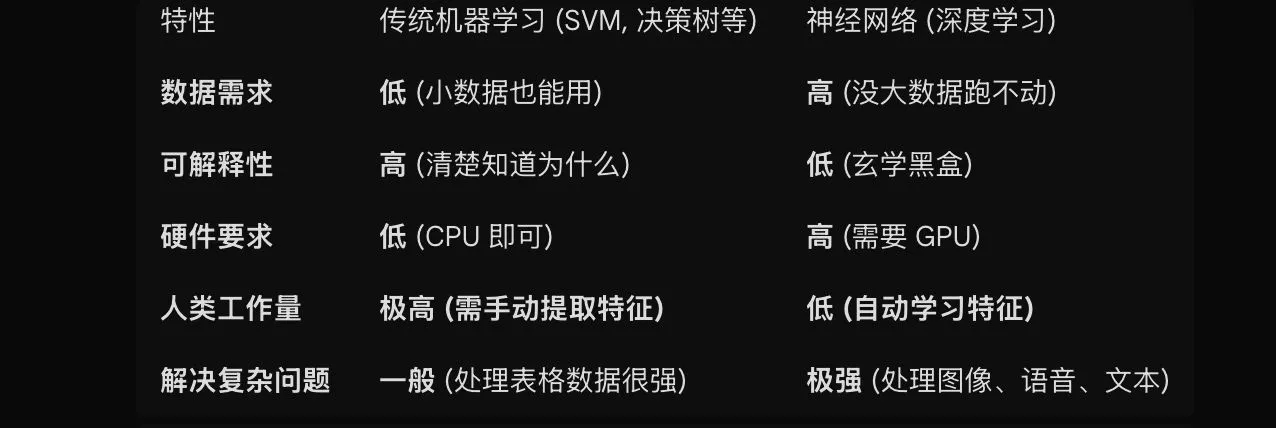
在传统的机器学习中,我们需要进行对特征值(指可以
从输入数据(输入图像)中准确地提取本质数据(重要的数据)的转换器)的构造,必须使用合适的特征量(必须设计专门的特征量),才能得到好的结果。
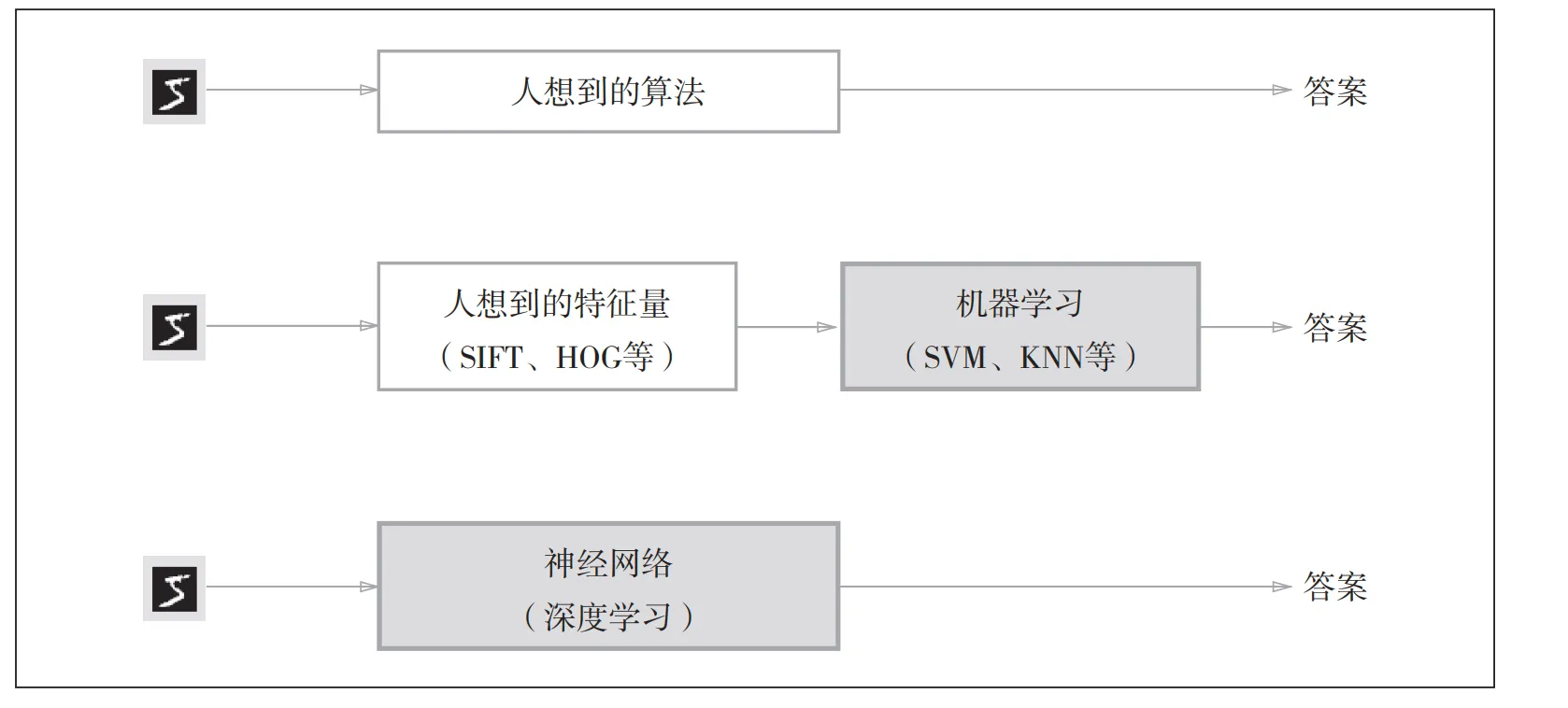
sift和hog会将图片的局部转化为特征,然后将局部的特征全部加在一起组成一个巨大的向量,然后将训练好的svm和knn的参数与这些向量做乘积,进而实现预测,请注意他是二分类的分类器,如果要对多个物体进行识别,那有两种措施,分别是一对多和一对一竞争


但是神经网络的优点在于,你不需要人为的构造特征,你可以完全将参数交给神经网络让其自己进行训练拟合,但是其缺点也是如此,过于黑盒导致其在某些置信度很高的地方你不敢去使用它,这就不得不提起我曾经在实验室中学习过的符号回归的相关问题。
在符号回归里面,使用过程中所得到的精度是通过计算方差和标准差得到的
在神经网络的训练过程中,我们通常将数据分为训练数据和测试数据,训练数据,
首先,使用训练数据进行学习,寻找最优的参数;然后,使用测试数据评价训练得到的模型的实际能力。
测试数据的存在性是为了测试模型的泛化能力,即实际应用的能力。
损失函数
我们在这个训练过程中以损失函数作为我们评判一个模型的预测好坏的标准。为了减小计算量,我们通常是选取mini_batch的训练数据来进行模型的评测,即进行损失函数的计算。
损失函数通常有两种选择,这两种选择通常是基于你所要解决的一些问题。
均方差函数


交叉熵函数
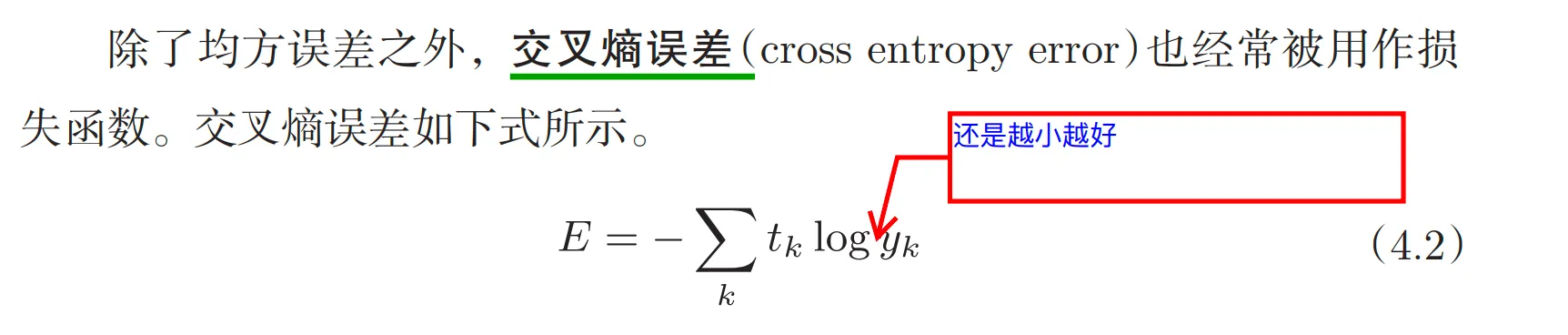

选择的原则,主要是为了让反向传播回去的乘积因子更加漂亮

为什么要设定损失函数呢?我们提高的难道不是精度吗?直接用精度来衡量模型的好坏不就好了?
为什么不选取阶跃函数作为神经网络的激活函数呢?如果使用了会有什么样的影响呢
我们设定损失函数的原因主要是希望可以通过一个平滑的连续的可导的函数来衡量当前模型的能力。如果使用精度,则其一定为分散的,不连续的,55%,56%,57%,当模型稍微改变自己的参数之后模型是不知道下一步应该走向哪边。但是如果使用损失函数,则可以得到很细微的改变从而告诉模型下一步调整参数应该如何进行才好
如果在神经网络的某一层中我们使用了阶跃函数,那么即使我们选取的是损失函数,参数的改变带来的作用是0或者1,即不会对结果产生影响或者影响过大,所以不能使用阶跃函数来作为激活函数
那么,可不可以某一层来使用阶跃函数呢?
我个人感觉是不行的,因为你需要更新每一层的权重,这意味着你需要梯度,(可不可以不使用梯度),如果你需要使用梯度,那么就需要用数值法进行梯度计算,要么用反向传递法进行梯度的计算。如果使用第一种计算梯度的方法,那么好像是不需要要求整个神经网络中的激活函数是连续可导的,但是如果是方向传播,则必然是可导的,否则你无法处理从前一层的神经元向后一层的神经元的参数的传递。
其实是不可以使用阶跃函数的,因为梯度的计算是每一层每一层的算,如果当前层使用了阶跃函数,那么就会造成要么为0,要么为无穷大的偏导数,这样的偏导数对于指导参数的调整是没有任何意义的

那么可不可以不使用梯度来进行呢?
-
进化算法 / 遗传算法
-
粒子群优化 (PSO)
-
单层的神经网络(感知机):

数值微分和反向传播算法
书上将其分为两张,但是在总结的时候我还是希望通过这样的一些对比来加深自己的记忆吧
数值微分中涉及到的数学概念有导数,偏微分,梯度。
- 导数:我们使用中心差分而不是数值微分的原因:
- 中心差分可以增大分母,从而避免出现舍入误差

- 中心差分可以减小误差,相当于用了拉格朗日定理,求得包含所求点点平均一段区间内的斜率,当区间长度趋向于0的时候与所求切线相差无几

- 中心差分可以增大分母,从而避免出现舍入误差
之所以称之为数值微分,是因为本身就是从数值过来的,存在误差。但是还有一种是解析推导,即计算函数的导函数,解析性求导得到的导数是不含误差的“真的导数
-
偏导数:

-
梯度:将全部的偏导数进行汇总从而得到梯度

通过作图,我们会发现一个很有趣的点,就是发现梯度指向函数的最低点。
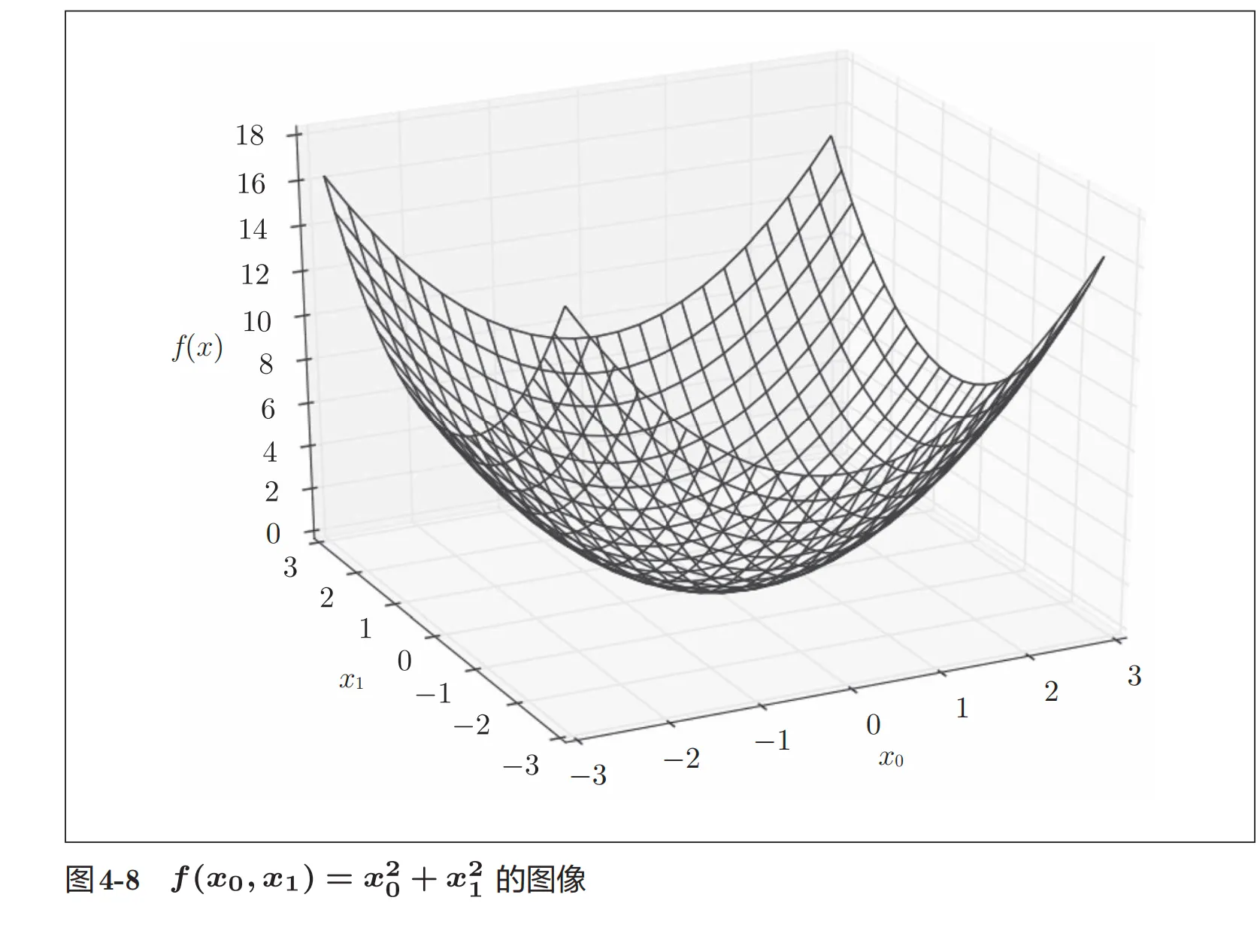
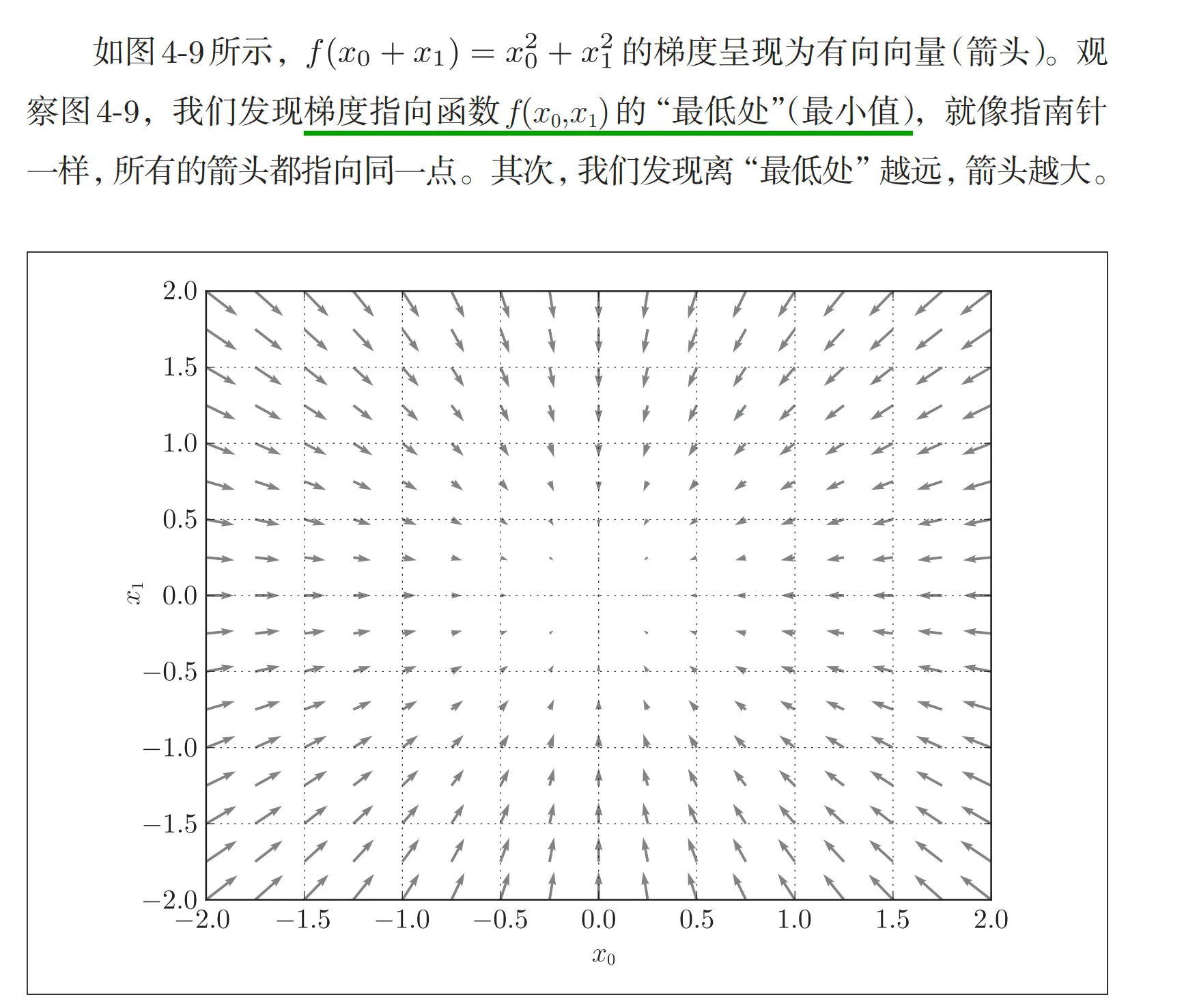
所以,梯度指示的方向是各点处的函数值减小最多的方向。虽然梯度的方向并不一定指向最小值,但沿着它的方向能够最大限度地减小函数的值,通过不断地沿梯度方向前进,逐渐减小函数值的过程就是梯度法(gradient method)

如果用代码来实现就是如下的代码片段

神经网络的梯度
 通过对比我们可以很容易的发现,权重和梯度的矩阵大小是一模一样的,这意味着乘以学习率就可以直接实现更新
通过对比我们可以很容易的发现,权重和梯度的矩阵大小是一模一样的,这意味着乘以学习率就可以直接实现更新
我们接下来需要实现的是定义一个
神经网络的类
- init部分(包含初始的权重)
- 第一层的参数和偏置
- 第二层的参数和偏置
- 方法
- 预测(向前传递:输入与当前权重的乘积)
- 计算该层输入和该层权重的点积
- 使用激活函数计算点积值
- 传给下一层的输入
- 计算损失函数
- 抽取minibatch的数据,进行预测并进行损失函数的计算
- 准确函数
- 用来检验最终得出的结论是否正确
- 计算梯度(反向传递)
- 计算损失函数关于第一层参数和偏置的梯度
- 计算损失函数关于第二层参数和偏置的梯度




- 预测(向前传递:输入与当前权重的乘积)
如果我们在某处得到的关于某个参数的梯度是正值,则我们可以减小该参数以实现损失函数的减小;反之同理
神经网络算法的实现
- 设置好初始化的权重和偏置
- 计算minibatch的损失函数
- 计算该损失函数的梯度
- 更新参数
- 重复234过程
minibatch的实现,注意看,这里使用的数据是训练数据,也就是说,我们使用随机的minibatch个训练数据来对神经网络进行训练,我们称epoch为将所有的训练数据都使用一遍的轮数,比如,对于 10000笔训练数据,用大小为 100笔数据的mini-batch进行学习时,重复随机梯度下降法100次,所有的训练数据就都被“看过”了,我们称之为一个epoch

当一轮epoch结束之后,我们会使用测试数据来衡量当前的精度

第二节:如何算得更快—误差反向传播算法!
在本节中,我们使用计算图来实现误差反向传播算法,我个人感觉这个计算图的引入简直就是神来之笔,通过分析节点处的传播参数的规律,通过引入有序字典表,我们可以很轻松的实现正向传递计算预测值和反向传递计算梯度值
计算图
计算图的简单应用
何为计算图
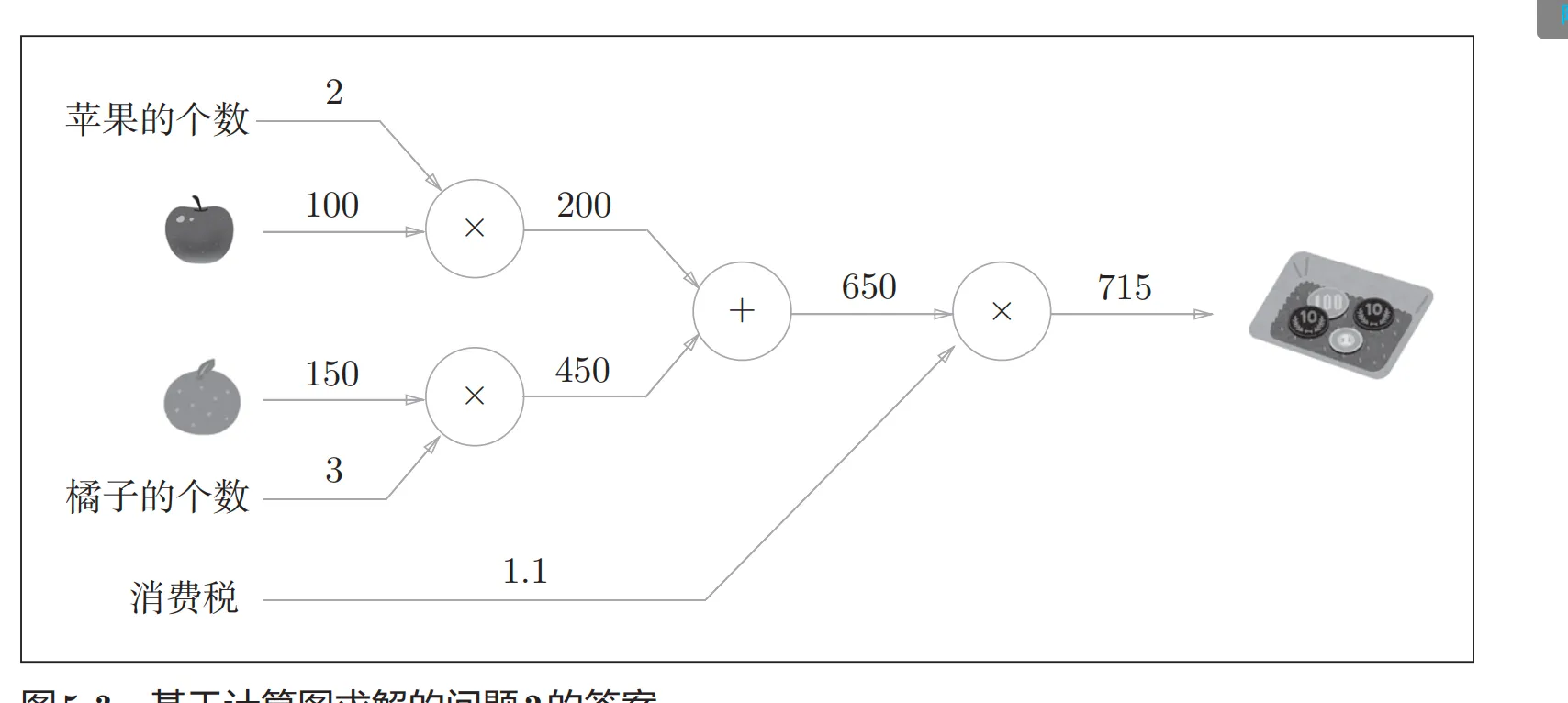
计算图的反向传播
简单层的原理和实现
-
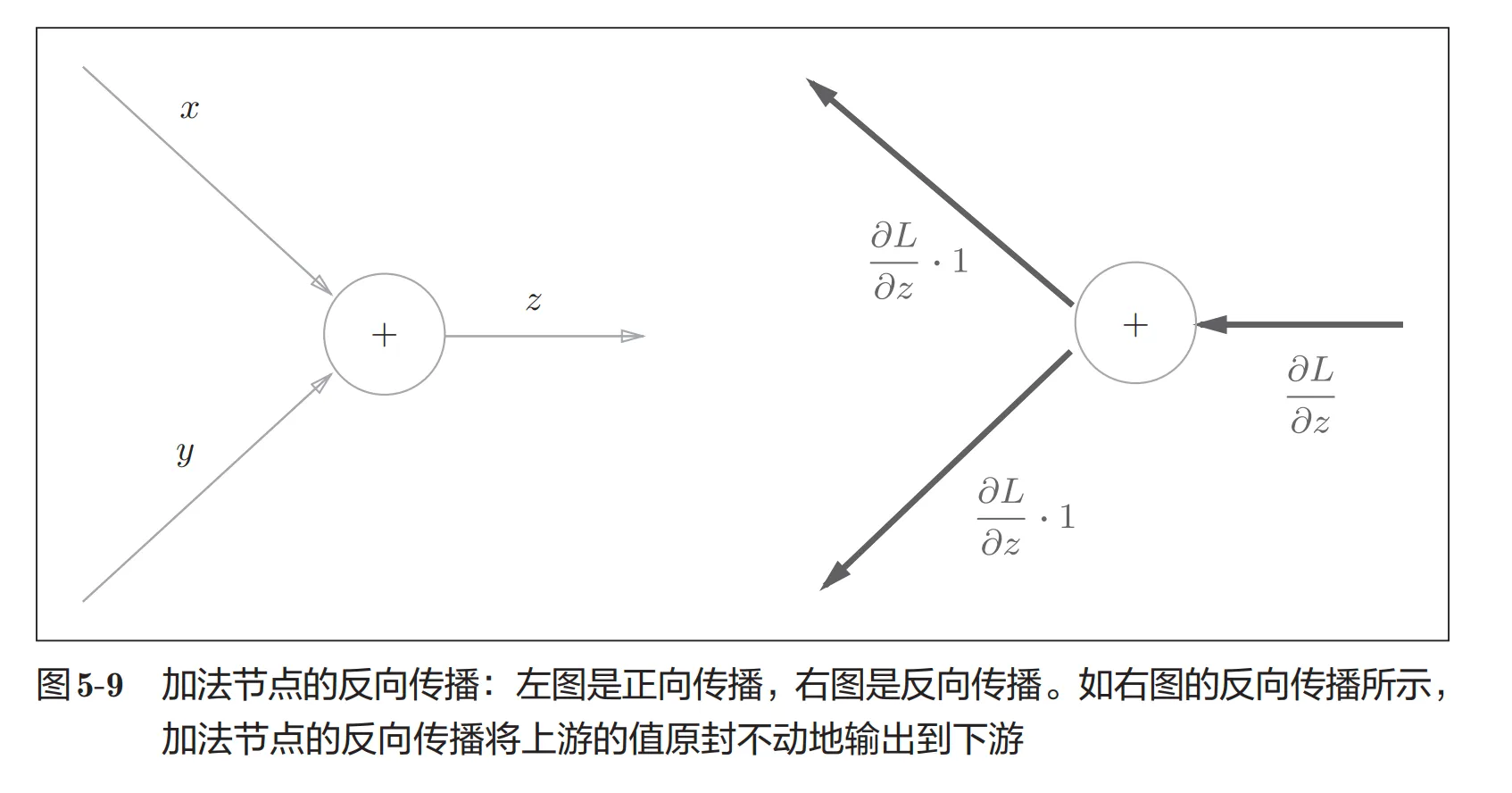
对于加法节点,直接传递参数
-
对于乘法节点,反向传递过来的值乘以另一边的输入值
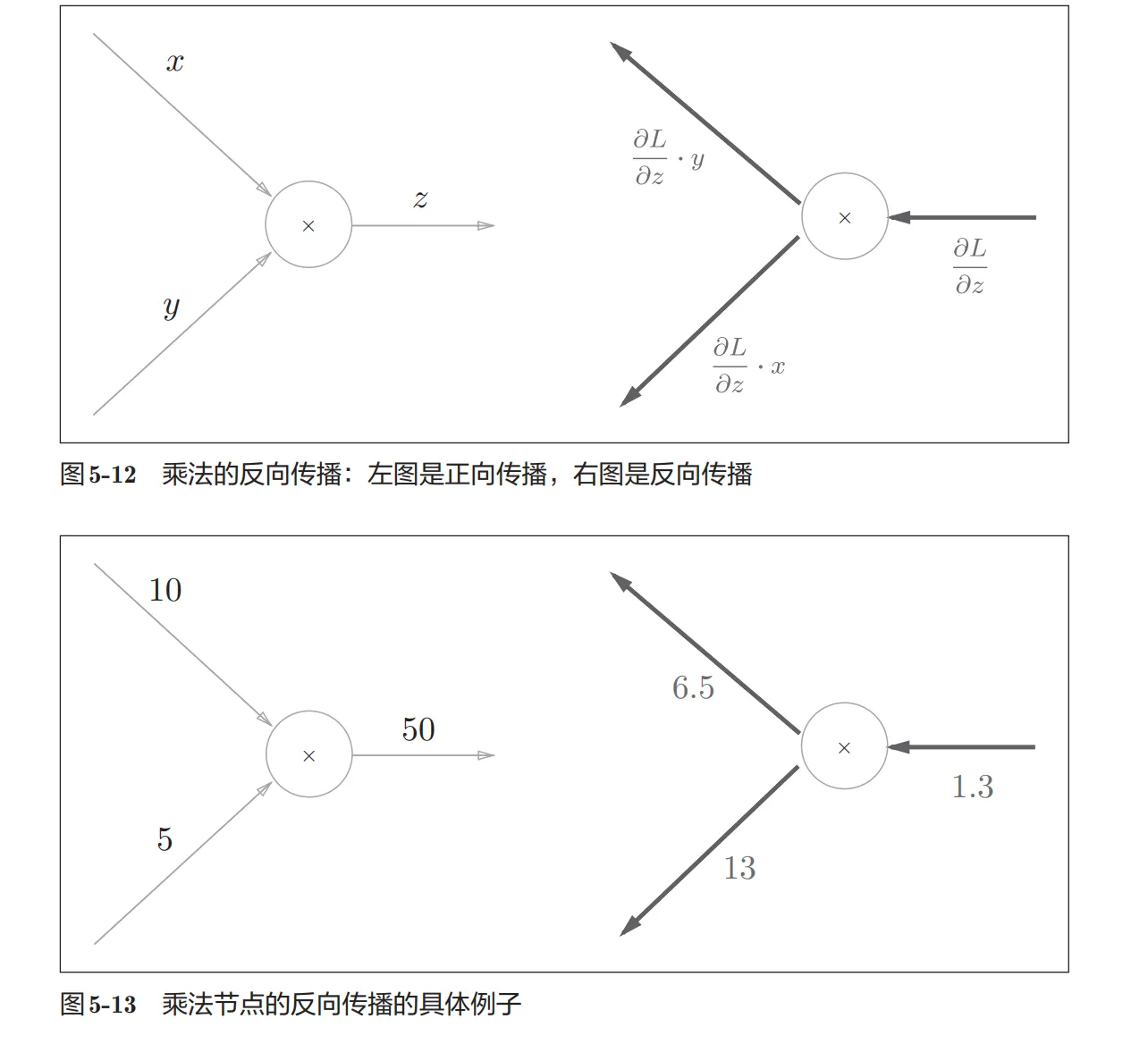
 所以需要存储原始的输入值从而计算该点的反向传播时候传递过来的值所需要乘的参数
所以需要存储原始的输入值从而计算该点的反向传播时候传递过来的值所需要乘的参数
 对于激活函数层的实现
对于激活函数层的实现
-
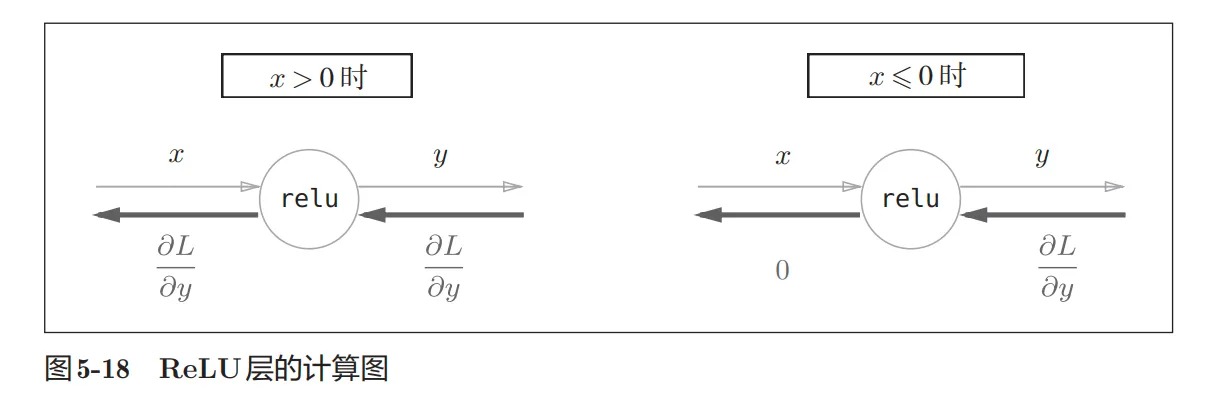
ReLU层:
- 函数形式:

- 计算图
- 代码实现:
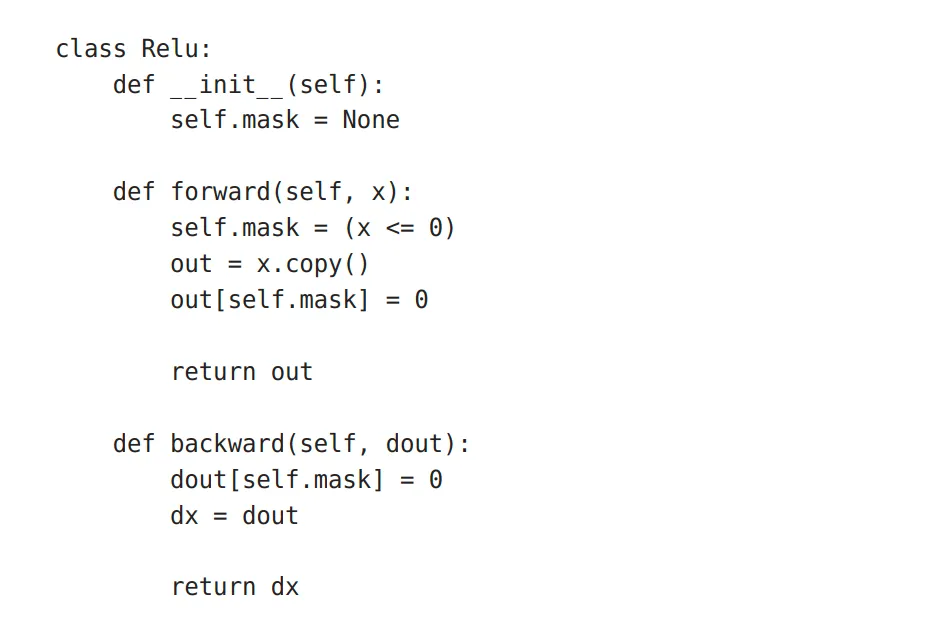 相关的说明:使用mask来实现对于正向传递和反向传递的统一管控,即输入小于0,输出为0,反向传递回来的乘积因子也为0;输入大于等于0,输出为输入,反向传递的乘积因子为1
相关的说明:使用mask来实现对于正向传递和反向传递的统一管控,即输入小于0,输出为0,反向传递回来的乘积因子也为0;输入大于等于0,输出为输入,反向传递的乘积因子为1
- 函数形式:
-
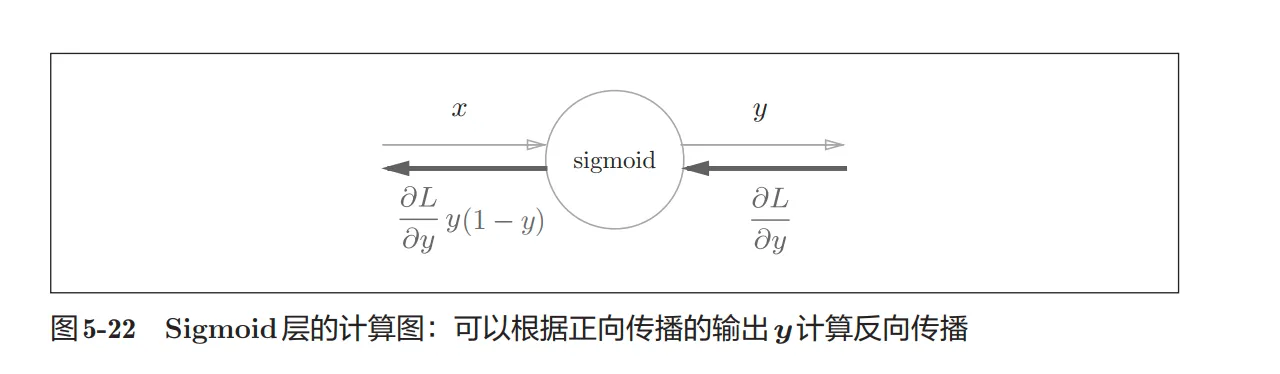
Sigmoid层
- 函数形式:

- 反向传播的形式:
- 代码实现:
 相关的说明,经过层层的推到,我们不难发现sigmoid层的反向传递的成绩因子和当前节点的输出是密切相关的,即$y*(y - 1)$,所以我们需要在这个节点的内部去存储当前的输出
相关的说明,经过层层的推到,我们不难发现sigmoid层的反向传递的成绩因子和当前节点的输出是密切相关的,即$y*(y - 1)$,所以我们需要在这个节点的内部去存储当前的输出
- 函数形式:
-
Affine层
- 定义:我们将正向传播中进行的矩阵的乘积运算在几何学领域被称为“仿射变换” ,而这个仿射变换我们称之为Affine层
- 传递形式:



函数的实现: 说明:在此之前,我想先回顾一下如何计算中间层的神经元的输入
说明:在此之前,我想先回顾一下如何计算中间层的神经元的输入
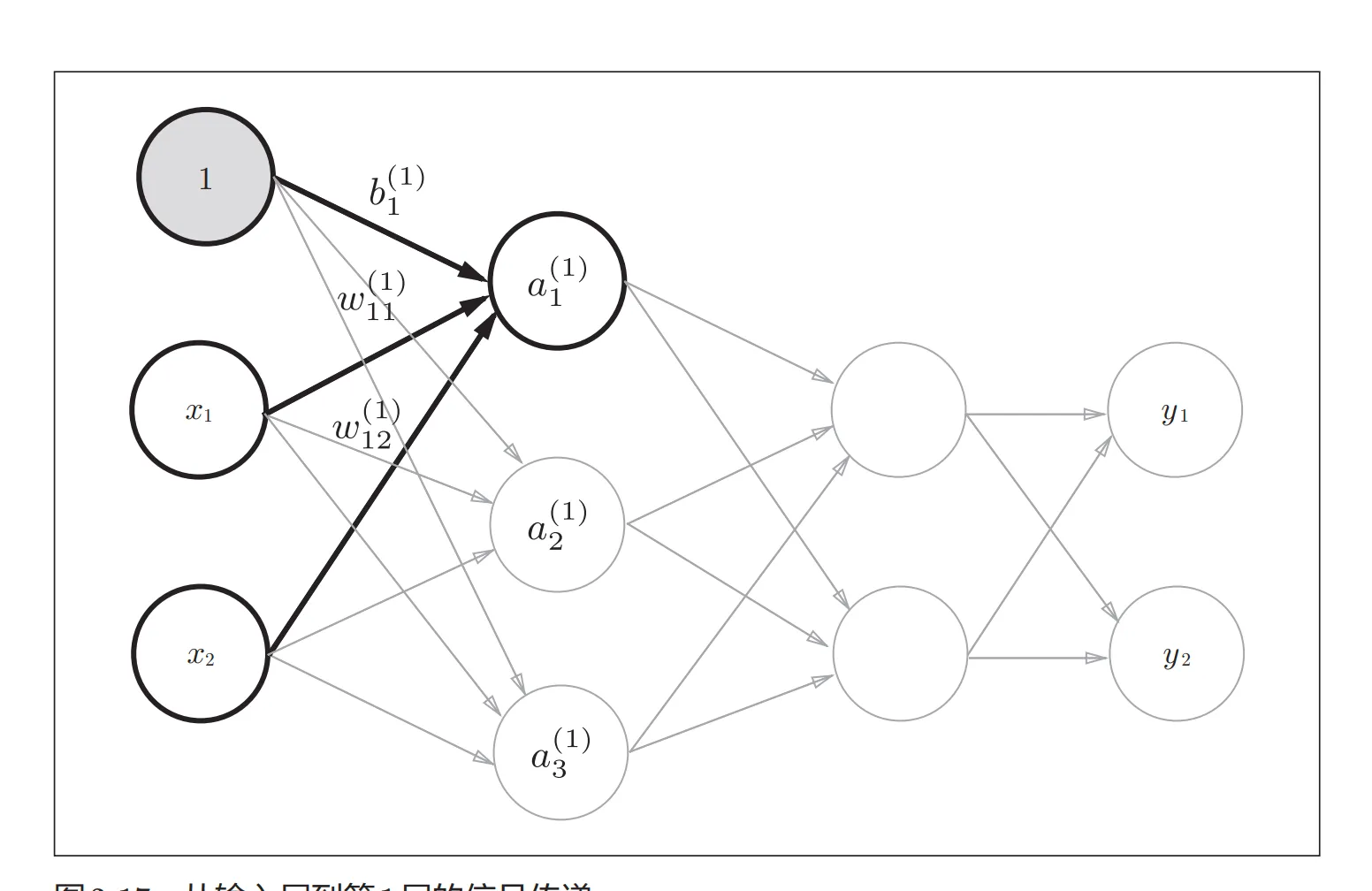 核心出装是:
核心出装是: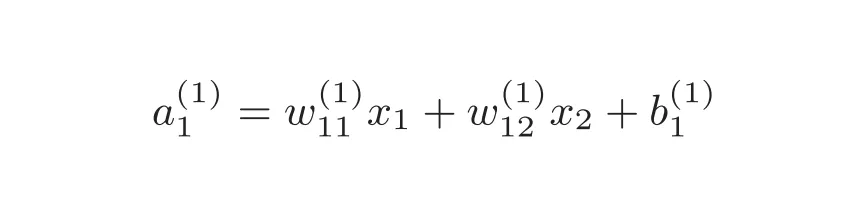
 从而其实很容易理解了
从而其实很容易理解了
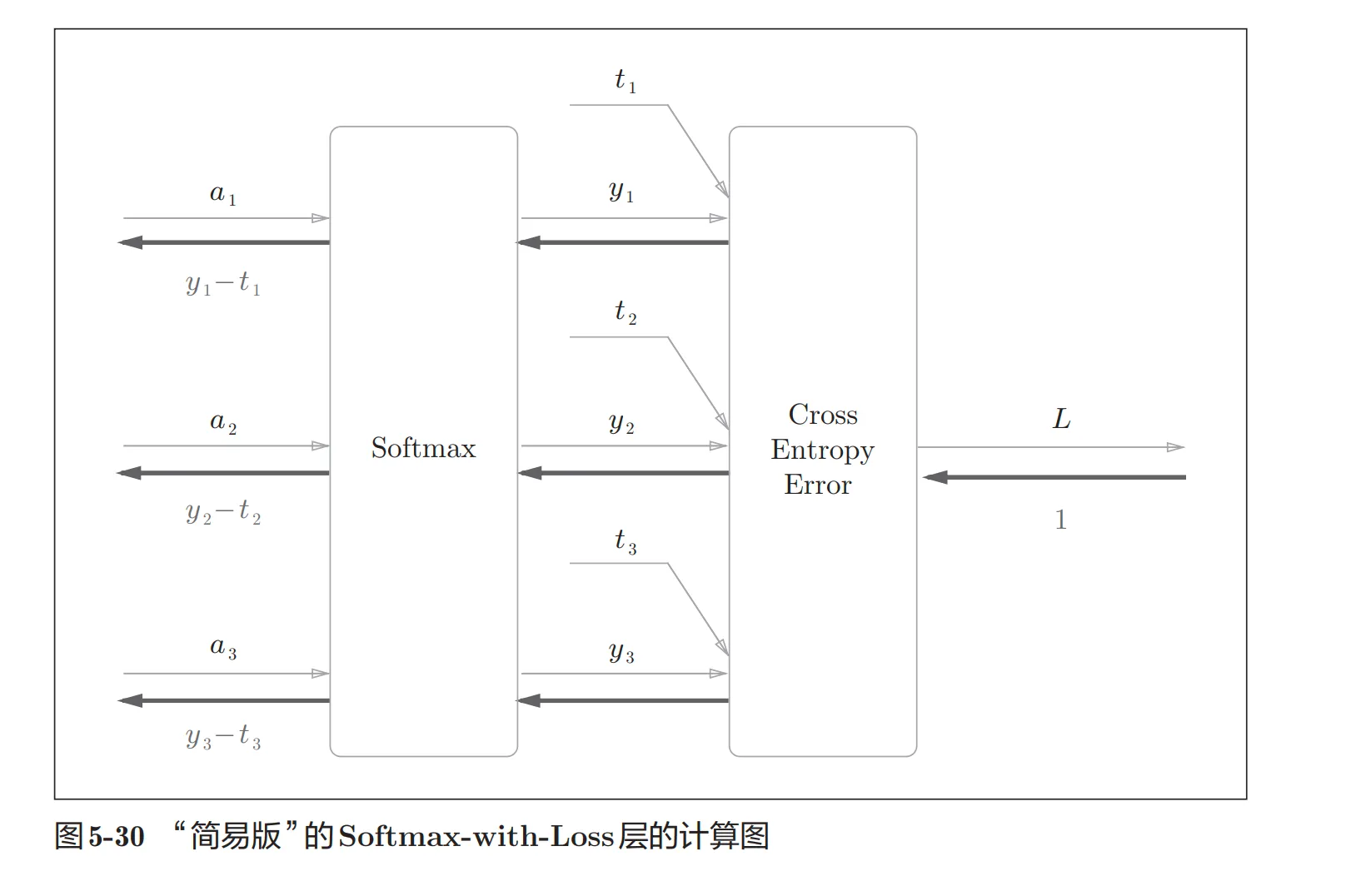
- SoftMax—With-Loss层
- 反向传播图:
- 代码实现:

- 正向预测:

- 反向传递参数:
 说明:易发现其实所有的类的反向传播都说都是在内部计算好存储在那个节点内部然后进行提取
但这种方法往往不能完全的保证正确性,所以我们通常会使用数值计算的方法来作为反向传播得到的梯度的验证
说明:易发现其实所有的类的反向传播都说都是在内部计算好存储在那个节点内部然后进行提取
但这种方法往往不能完全的保证正确性,所以我们通常会使用数值计算的方法来作为反向传播得到的梯度的验证