深度学习第二天
学习内容 : 神经网络
神经网络:输入层 -> 中间层 -> 输出层
激活函数:对于感知机,使用的是阶跃函数 其余时候可以使用sigmoid函数来出现 还有ReLU函数,大于0时候,输出自身,小于0的时候输出为0
sigmod函数相比于阶跃函数更加的平滑,感知机中流动的是0,1这种二元信号,而神经网络中流动的是连续的实数值信号;二者的共同点是当其小的时候靠近0,大的时候靠近1; 同时激活函数不能使用线型函数,因为如果是线型函数,那么神经层数的增加遍显得毫无意义 接下来介绍了矩阵乘法,即线性代数的相关知识 接下来介绍神经网络的结构
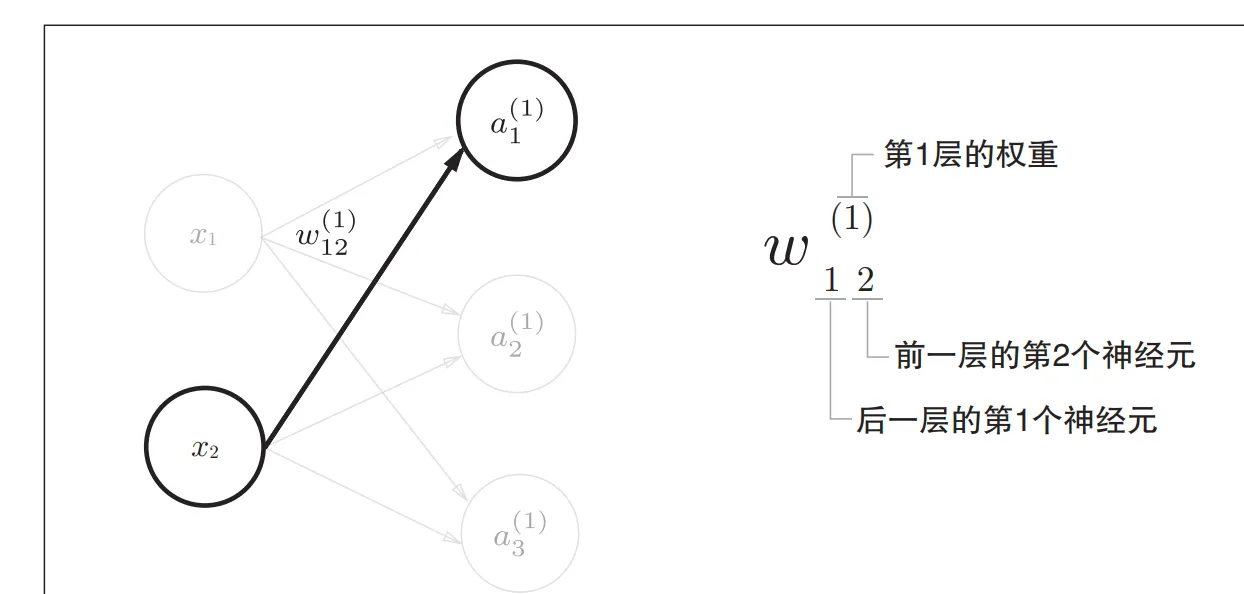
$a_1^{(1)} = \omega_1^{(1)}x1+\omega_2^{(1)}x2+\omega_3^{(1)}x3+b_1^{(1)}$
以下是包含激活函数的神经元的截图,
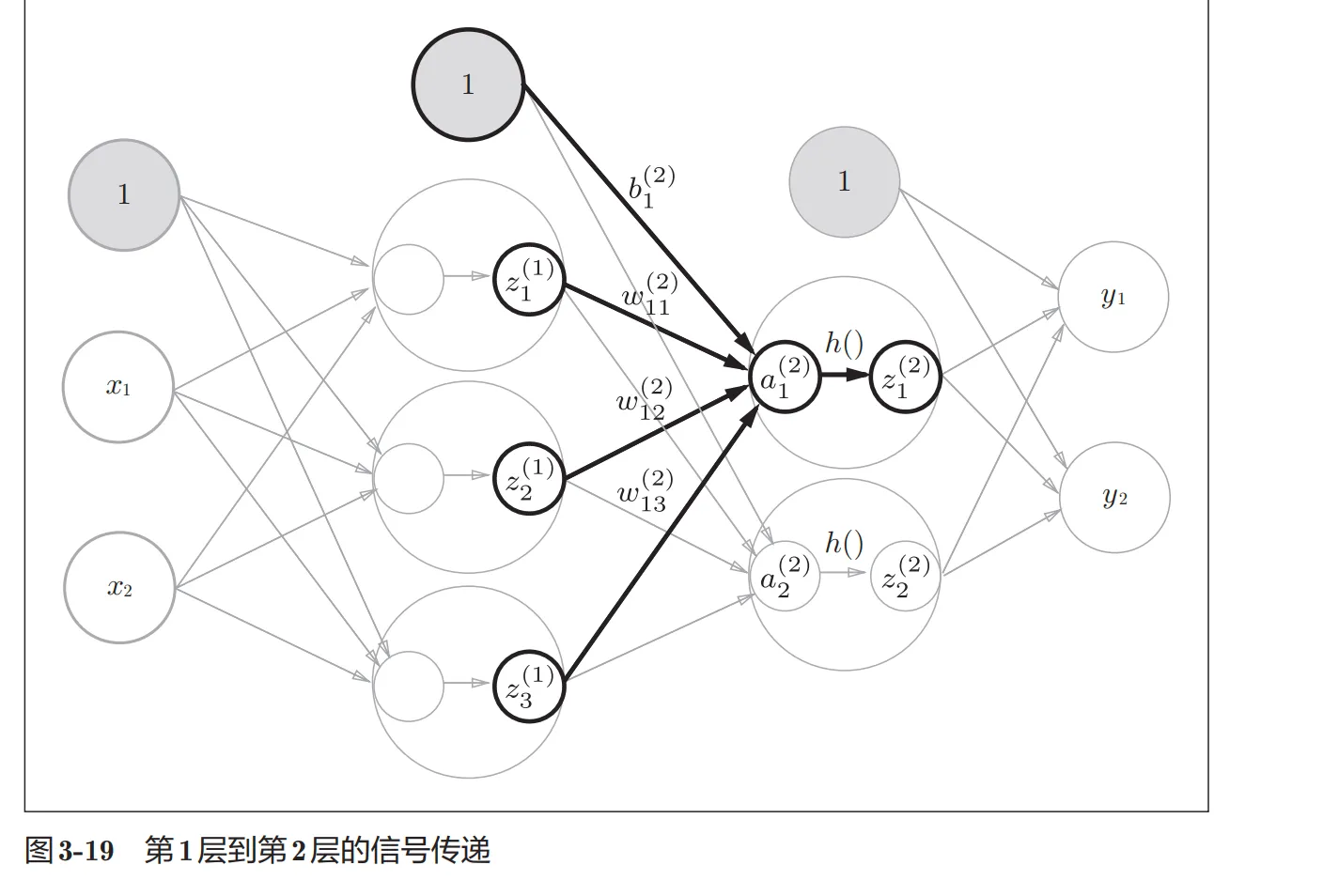
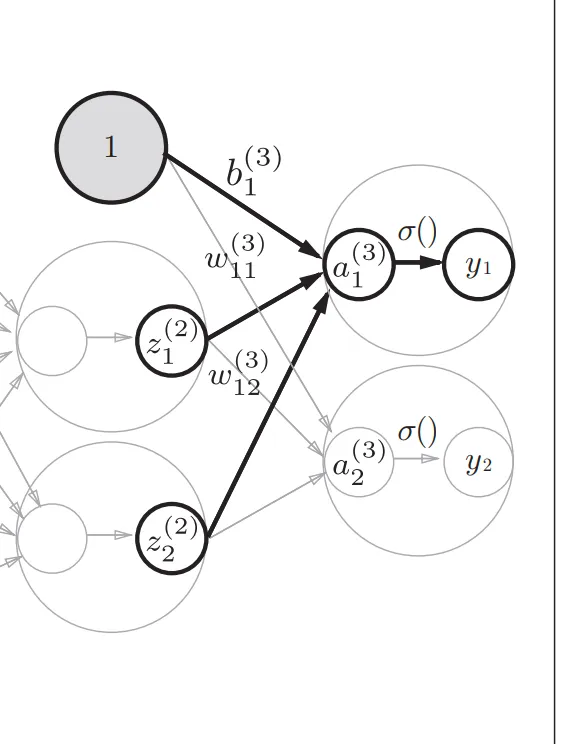
输出层使用的激活函数一般根据具体问题来分析。回归问题用的是恒等函数,二分类问题用sigmoid函数,多元分类用softmax函数来实现
 这就是softmax公式,用这个公式可以把输出的总和为1,但是在过程中会用到一些问题,比如指数的计算是有范围的,我们可以通过下式的增加和修改常数来实现使得计算结果不溢出。
这就是softmax公式,用这个公式可以把输出的总和为1,但是在过程中会用到一些问题,比如指数的计算是有范围的,我们可以通过下式的增加和修改常数来实现使得计算结果不溢出。
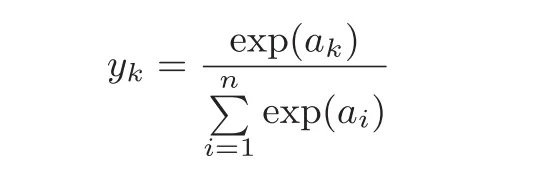
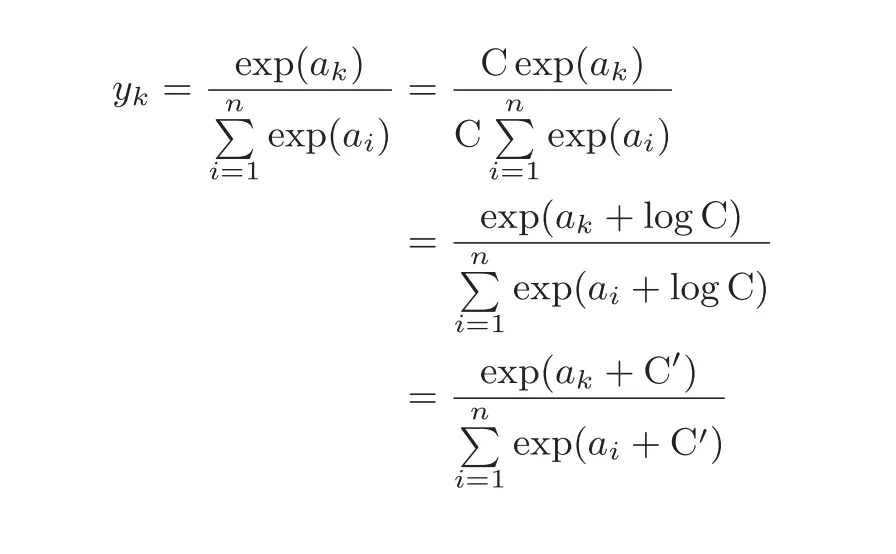
softmax函数又被称为是概率,他最终得出的输出和原始数据通过比较大小得到的输出是一致的。 所以在输出层,我们一般不需要进行softmax操作,毕竟计算也是需要时间的。但是在训练神经网络的时候,你需要让你的神经网络知道自己错了多少,错的有多离谱。通过softmax函数,存在所谓的跷跷板效应,统一度量衡(归一化),且存在比较光滑的可导性 想区分一些简单的概念:
- 导数:导数 = 只有一条路时的坡度
- 梯度:先求各个变量的偏导数,再将其组合成一个向量,这个向量指向参数变化最快的方向
- 学习率:$W = W - 学习率*梯度$
在这个过程中,我们想实现的是让损失函数往小的方向发展
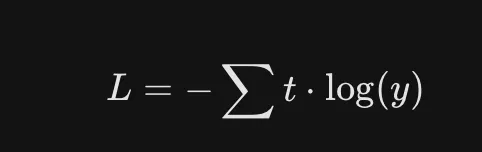


在此过程中,我们使用的是独热码,使用我们可以提取出所预测目标的参数值,如果是索引,那直接取这个参数的预测概率即可。
从而引入了一个检测数的一个训练好的神经网络,然后让你进行一个简简单单的体验。 在此过程中所学习了很多的python语法,比如
sys.path.append(os.pardir)(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)展平的意义是因为神经网络不能处理多纬的数据,所以需要将28*28的图片数据转化为线形的数组
img = x_train[0] # 取出第一张图的数据
print(img.shape) # 输出 (784,) -> 这就是刚才 flatten=True 的结果
img = img.reshape(28, 28) # 【关键步】把图像的形状变为原来的尺寸
print(img.shape) # 输出 (28, 28) -> 变回正方形def img_show(img):
pil_img = Image.fromarray(np.uint8(img))
pil_img.show()
img_show(img)np,unit8(img)是为了实现将图片转化为合适的图片像素,
Image.fromarray(…):把 Numpy 的数组(纯数字矩阵)转换成 PIL 的图像对象。
os (Operating System): 它的作用:和你的操作系统(Windows/Mac/Linux)打交道。
你可以把它想象成 Python 里的 “文件资源管理器”或“命令行终端”。凡是跟文件、文件夹、路径、环境变量有关的操作,都找它。
常用功能:
os.getcwd(): 告诉我当前在哪里?(Get Current Working Directory)
os.mkdir('新文件夹'): 帮我建个文件夹。
os.path.exists('a.jpg'): 看看这个文件存不存在?
在你代码中的作用 (os.pardir):
pardir 是 Parent Directory(父目录/上一级目录)的缩写。
在大多数系统里,它等同于字符串 ’..’。
意思就是: “指代当前文件夹的上一层”。
- sys (System-specific parameters)
它的作用:和 Python 解释器(Python 程序本身)打交道。
你可以把它想象成 Python 的**“系统设置”或“控制面板”**。凡是跟 Python 运行环境、模块搜索路径、解释器版本有关的,都找它。
常用功能:
sys.version: 告诉我现在的 Python 是几点几版本?
sys.exit(): 立刻强制退出程序,不跑了。
sys.argv: 获取命令行运行时输入的参数。
非常重要: 当你写 import xxx 时,Python 不会全盘扫描你的硬盘,它只会去 sys.path 列表里列出的那些文件夹里找 xxx.py。如果这些文件夹里都没有,它就报错说找不到。
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)
在这里我们使用的是让其正则化,这样就可以实现在sigmod的中间导数比较大的区域进行计算,从而会避免梯度消失的风险
在训练过程中我们可以使用矩阵进行计算,即一次性传入多个输入数据
batch_size = 100 # 批数量:每次打包处理 100 张图片
accuracy_cnt = 0 # 计数器:用来记录一共猜对了多少张
# 循环遍历数据集 x
# range(start, end, step):从0开始,每次跳跃 batch_size (100) 步
# 比如:i 会依次变成 0, 100, 200, 300...
for i in range(0, len(x), batch_size):
# 1. 取出一批数据
# x[i : i+batch_size] 是切片操作
# 比如第1轮:取出 x[0:100] 这100张图
# 比如第2轮:取出 x[100:200] 这100张图
x_batch = x[i:i+batch_size]
# 2. 批量推理(预测)
# 把这 100 张图一次性扔给神经网络
# y_batch 的形状是 (100, 10) -> 100张图,每张图有10个类别的概率
y_batch = predict(network, x_batch)
# 3. 找出最大概率的索引(获取预测结果)
# axis=1 非常关键!表示“沿着行”找最大值。
# 因为每一行代表一张图片,我们要分别找出这100张图各自概率最高的那个数字。
# 结果 p 是一个长度为 100 的数组,比如 [7, 2, 1, 0, 4, ...]
p = np.argmax(y_batch, axis=1)
# 4. 对比答案并统计
# t[i:i+batch_size] 取出这 100 张图对应的标准答案(标签)
# (p == t[...]) 会生成一个布尔数组,比如 [True, False, True, ...]
# np.sum() 会把 True 当作 1,False 当作 0 进行累加
# 算出来的结果就是这一批里猜对的个数,加到总计数器里
accuracy_cnt += np.sum(p == t[i:i+batch_size])
# 循环结束后,accuracy_cnt 就是整个数据集中预测正确的总数量
# 最后通常会算准确率: float(accuracy_cnt) / len(x)